Last time I wrote about the talk by Christian Sauter regarding knowledge graphs and reasoning engines with an emphasis on how they fit with other kinds of artificial intelligence (AI) solutions for particular use cases1. I’m new to the concept of a knowledge graph but I know about graphs and about other kinds of AI. In this series of posts I’ll try to contextualize the new concepts that I’m learning about with some more familiar ideas using a specific example: my personal collection of notes. I’m particularly interested in getting to grips with the concept of semantic data.
In this post I’ll take a look at an example of a graph and examine its structure by looking at the communities that form it. While you could argue that there’s semantic similarity between the members of each community, it’s clear that this is not quite the same as what people mean when they talk about semantic data in a knowledge graph. In my specific example here I found this difference to be akin the difference between intuition and logic in a human mind, and I found the contrasts and parallels illuminating.
A bunch of notes
I’ve been keeping a personal knowledge management (PKM) system for a few years now collecting notes about many topics that catch my eye. I loosely follow the Zettelkasten method2 in a digital medium. The basic idea is very simple: you write simple notes and then link them. Something like this:
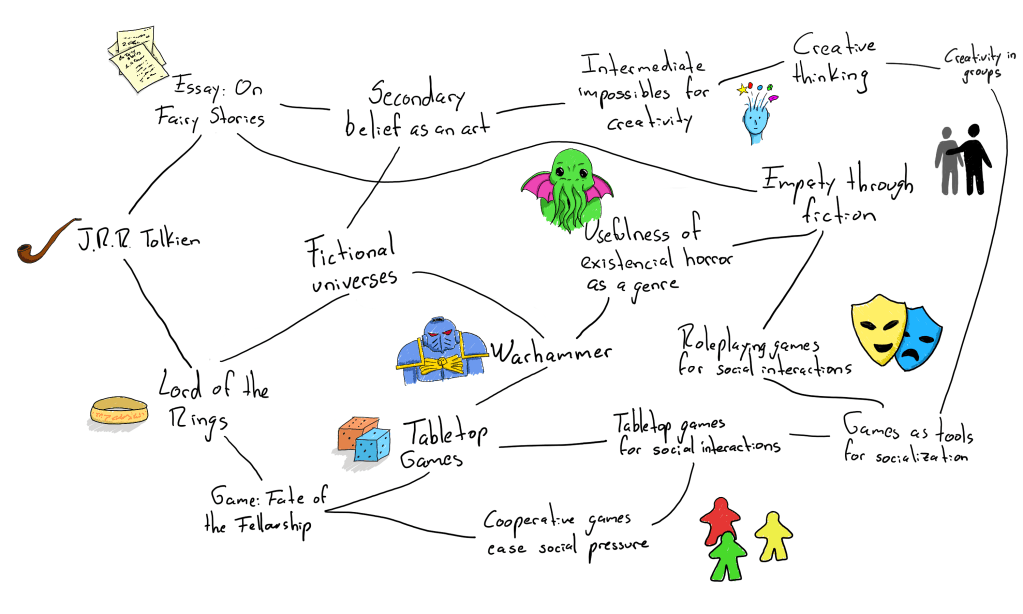
The lines are just one note mentioning another somewhere in its content. This is the essence of what a graph is, a collection of nodes with edges between them. I have a bit over a thousand notes so far with many connections between them. We can have a bird’s eye view of them by just representing each note with a circle and a link with a line. In my case it looks something like this
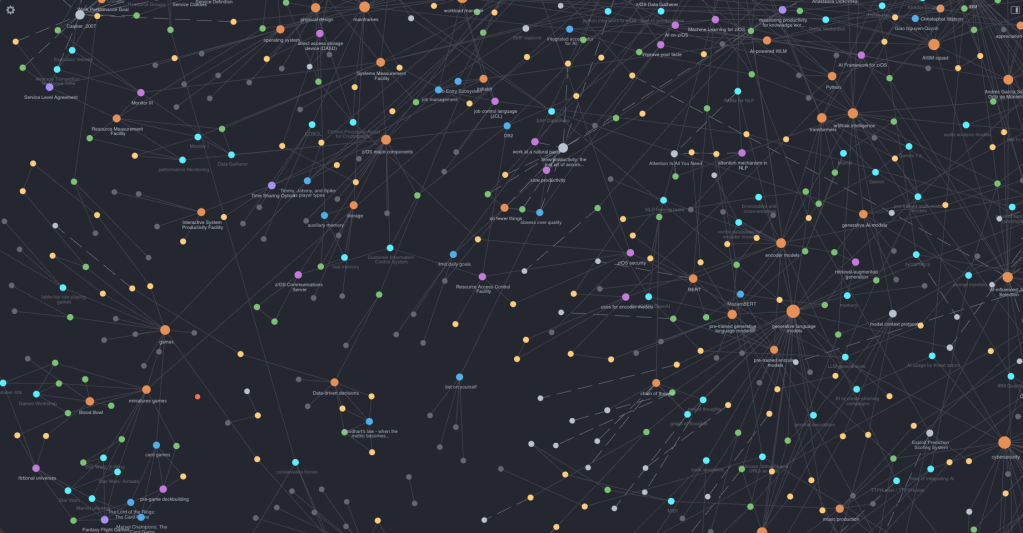
You can look at some much more impressive examples online3. I’ve not found that kind of visualization very useful, but there’s one thing that they show: you can see some clusters of notes. There are places where you have many notes connected between them. Turns own, your can automatically detect them.
Communities of notes
In graph theory there’s the concept of a community, which looks like exactly this: a group of nodes more connected within themselves than with other nodes. This is a perspective I can easily adopt for my PKM notes. I was able to export my notes into a suitable format, which is basically with a unique identifier for each note and then a list of connections between them. I included also the title of the note for later, but it’s not needed for the community detection. Here is how the data looks like:
{ "nodes": [ { "id": "20260209T111812", "name": "Table-top roleplaying games (TTRPG)", }, # more nodes... ], "edges": [ { "source": "20260128T140650", "target": "20260128T125604", }, { "source": "20260512T165754", "target": "20260512T165407", }, # more edges... ]}
With this I used the leidenalg package for python4 for detecting the communities and then I asked the gemma3 model in Ollama5 to come up with a name for the community given the titles. Here is the result:
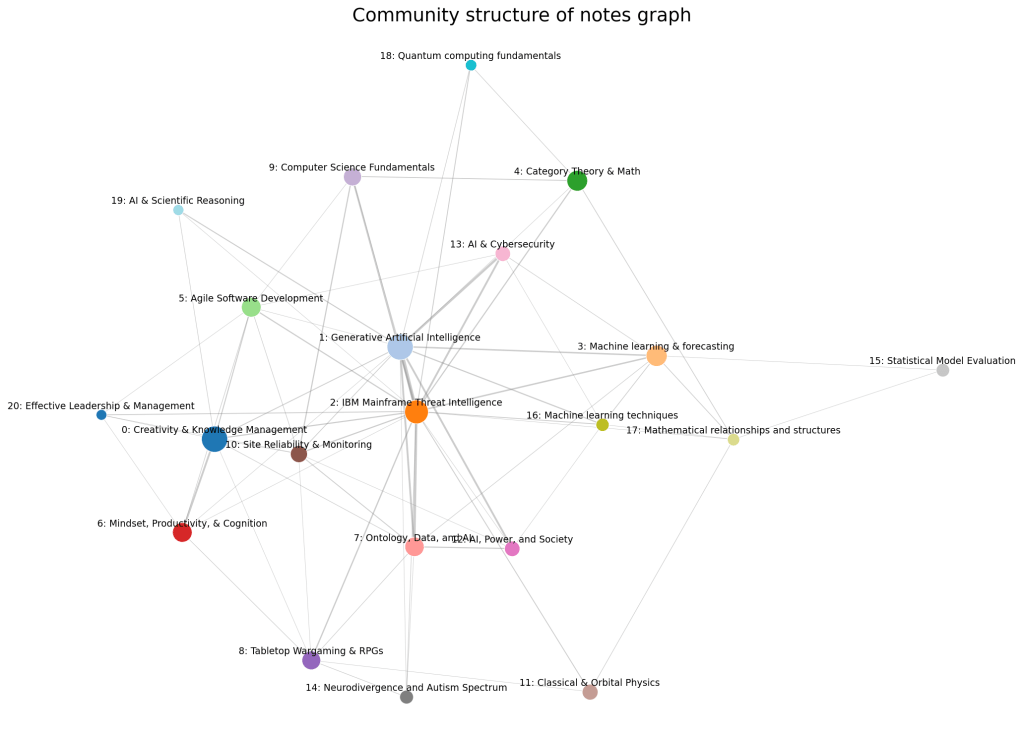
I feel that this is a sensible community detection of my notes. Roughly speaking they represent my broad interests and work history. I spent some time looking at the individual notes and there’s nothing obviously out of place. There are, of course, some debatable choices but in life it’s rare to be able to separate something into neat separate boxes anyway6.
Does this mean that the algorithm has somehow found the meaning in the data and was able to cluster them based on a semantic similarity, or is something else going on?
Did we find the semantics in the data?
The notes inside each community certainly seem to be semantically similar but we never looked at the actual content of each note, in fact even the titles were not used, only the non-descriptive ids. How then did we find something semantically meaningful?
First of all, the community detection algorithm is entirely concerned with the structure of the graph, not the contents of each node in it. The only meaningful difference between one node and another is the connections that they have. It’s like that saying my parents used to repeat “tell me who you hang around with, and I’ll tell you who you are.”7 We say two notes are related just because they hang around with the same group of friends. We uncovered a structure in the graph, not any kind of semantic similarity. But the notes are clearly semantically related. Why is that? It’s simply because each link was made in the first place by a person (me) based entirely on the content of each note in the context of an existing corpus of other notes. In other words, while I was writing and linking the notes I was piecemeal creating that graph structure based on the semantic content of them. The community detection only presented the already existing semantic connections in a particular form.
At the end of the day, whether you’re talking about a PKM or a knowledge graph, any semantic content will always be traced back to a human making a decision somewhere. This can be in the form of a loose, sometimes intuitive relation like I’ve been doing so far with my notes. It can also be a formalized model of a part of the world with more precise definitions and rules. Meaning is always contextual and relational, asking for the semantic content of the data is asking how that data fits into a broader picture. But that picture is always drawn by human decisions, so the semantic content is always related to them.
Which leads me to the core of the reason of why my PKM is not a knowledge graph and the semantic relations found here are fundamentally different from the concept of “semantic data” in knowledge graphs. I’ve been building my PKM by writing notes and linking them but I’ve never made a distinction on what each note represents. I have a note on “J. R. R. Tolkien” and a note on “Astrodynamics”. For my PKM those are both just notes, there’s no distinction. Similarly a link between “The Hobbit” and “J. R. R. Tolkien” looks exactly the same as a link between “The ideal rocket equation” and “Astrodynamics”. I’m just saying there is a connection between them, I’m never stating how they are connected. In a knowledge graph you need to make those distinctions clearly.
All of this feels like a strong parallel between the System 1 and System 2 models of the mind popularized by Kahneman8. While writing my PKM I’ve been using my intuitive (System 1) mind but for a knowledge graph I need to engage my analytical (System 2) mind. It’s not enough to say “The Hobbit is related to J. R. R. Tolkien”, I need to specify that “The Hobbit” is a book, that “J. R. R. Tolkien” is a person and that the first was written by the second. There’s a lot to unpack there starting from defining the classes that my notes are allowed to have and which relations are allowed between them. There’s many more decisions that I’d have to make and each decision will define the semantics of the data. First I need to define a particular model of the world: what kinds of objects are allowed to exist in it (classes), how are they allowed to relate to each other (relation types) and any rules that it should follow (reasoning rules). Then any data point living in that model of the world will acquire semantic content based on both, its place in that world and how it relates to other data points in it.
Before going deeper into knowledge graphs, I’ll first go to the other extreme of what we’ve done here. I want to explore semantic embeddings, which is yet another way on which people assign semantic content to data. While community detection algorithms only look at the connections between notes, with a semantic embeddings approach we’ll look only at the actual words and phrases inside each of the notes and ignore their links entirely.


Leave a comment